Here’s a question for ya: What’s your level of understanding of artificial intelligence (AI) and machine learning (ML)?
It seems every marketing department on earth is tossing those acronyms around aimlessly to describe how their tool does what it does.
But, if we are going to tout a form of tech in our marketing, we better have a foundational understanding of how it works.
In this blog, I’m going to start exploring the world of Supervised and Unsupervised Machine Learning: what it is, how to train it, and when to use it.
Let’s dive in.
What is Machine Learning (ML)?
First off, let’s define machine learning: ML is a subset of AI that gives computers the ability to learn and make decisions based on data WITHOUT explicit instructions.

An easy way to conceptualize this is by thinking of spam filters. Spam filters are great examples of machine learning because they’ve been given two types of emails: spam and not spam. Then, they’re asked to identify the spam emails based on their learning and pattern recognition and sort them and put them into your spam filter.
Simple(ish)!
Now, the process of training a model doesn’t happen overnight. Why? Because learning takes time, even for robots with a faster learning curve than your above-average person.
But just like machine learning lives beneath the umbrella of AI, there are different types of machine learning that live under the ML label.
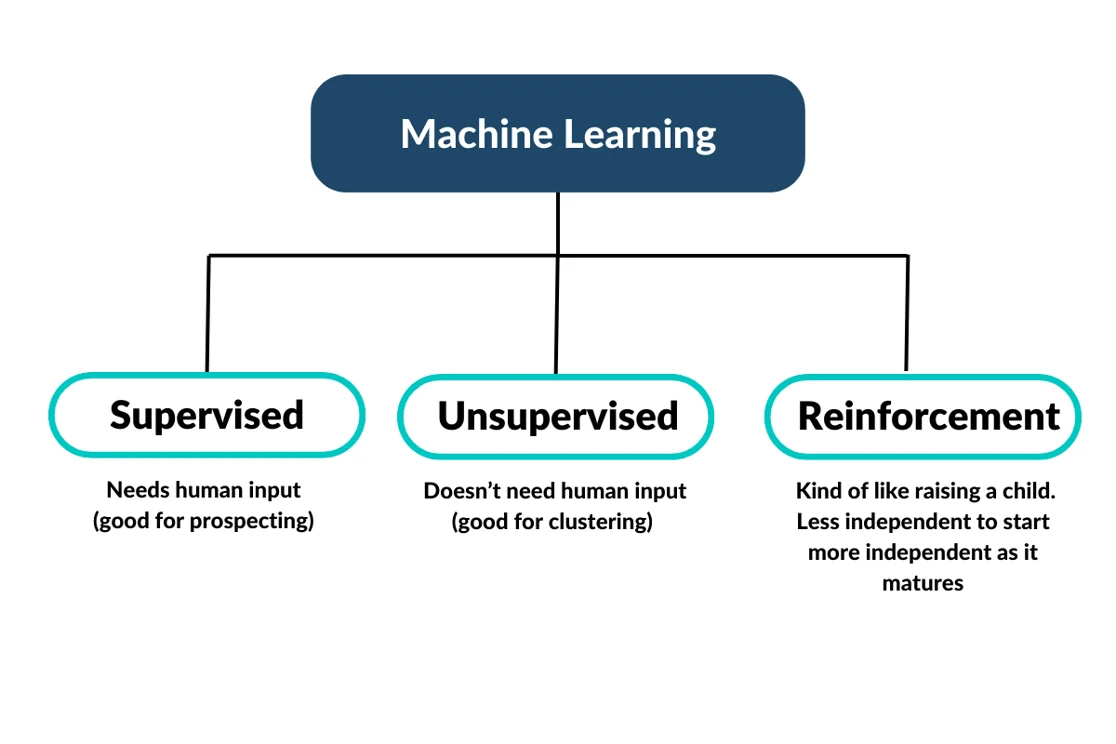
Under the different types of machine learning are various models used to train them.
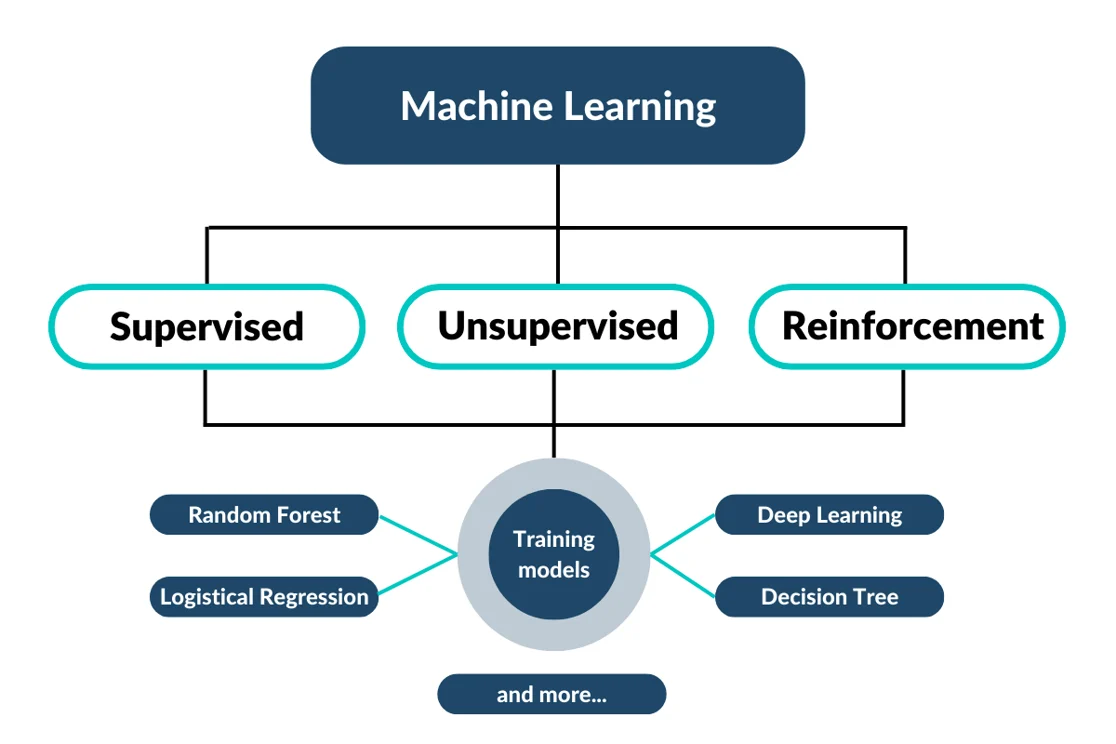
It’s probably becoming apparent at this point that you can go DEEP into the data science rabbit hole.
But for now, we’re narrowing our aperture and focusing exclusively on supervised machine learning and two standard models we use to train it.
What is Supervised Machine Learning (SML)?
SML is a type of model that is guided (supervised) by labels associated with datasets to train algorithms that accurately predict outcomes that humans influence with a known correct answer.
We apply them here at Postie when we help our customers build LAL models for prospecting campaigns. In prospecting campaigns, the seed audience we input represents top-performing customers that we want to use to find new customers that look similar.
But the key to SML success lies in its training.
Based on the size of audience you’re looking to send we recommend two options.
Random forest: best for smaller sized audiences
Deep learning: better for larger audience sizes
What is Random Forest?
In essence a random forest model takes your sample audience and isolates the top decile most likely to convert by asking a variety of qualifying yes/no questions.
The type of questions you have the model ask are dependent on the traits of the audience you’re looking to isolate.
So let’s say, for example, you’re looking to isolate high earners, living in the Austin, TX area, with kids.
Your questions might look a bit like this.
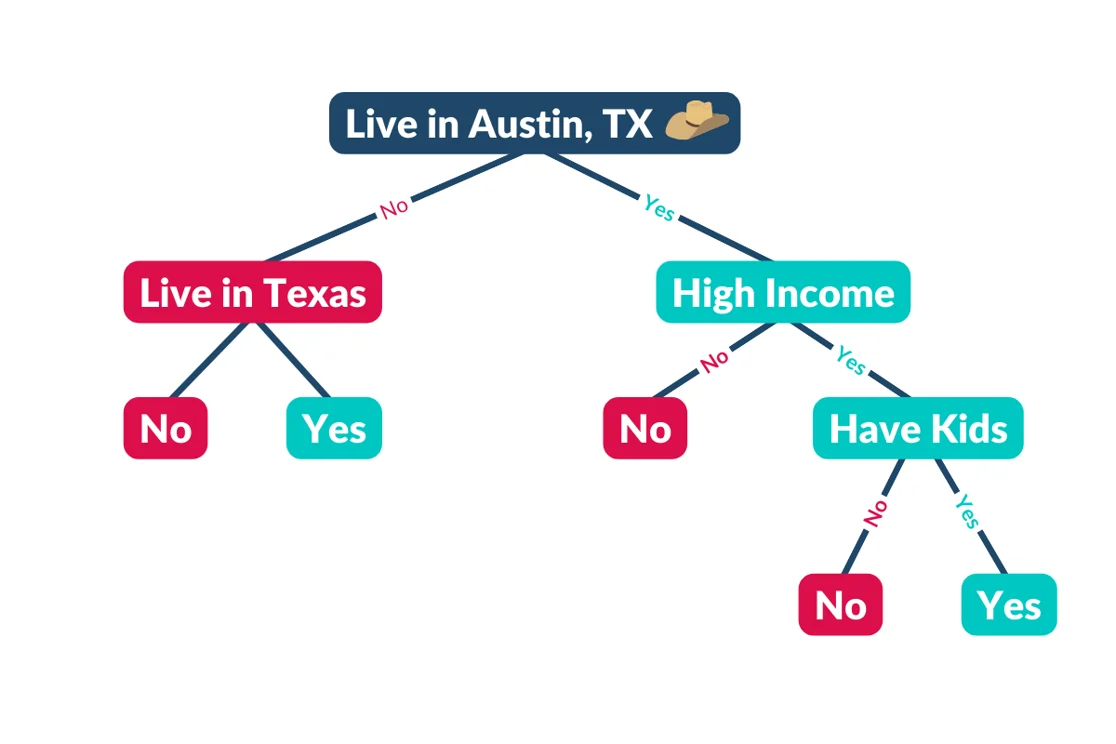
Ultimately, the model tries to isolate the best contacts with the least number of questions.
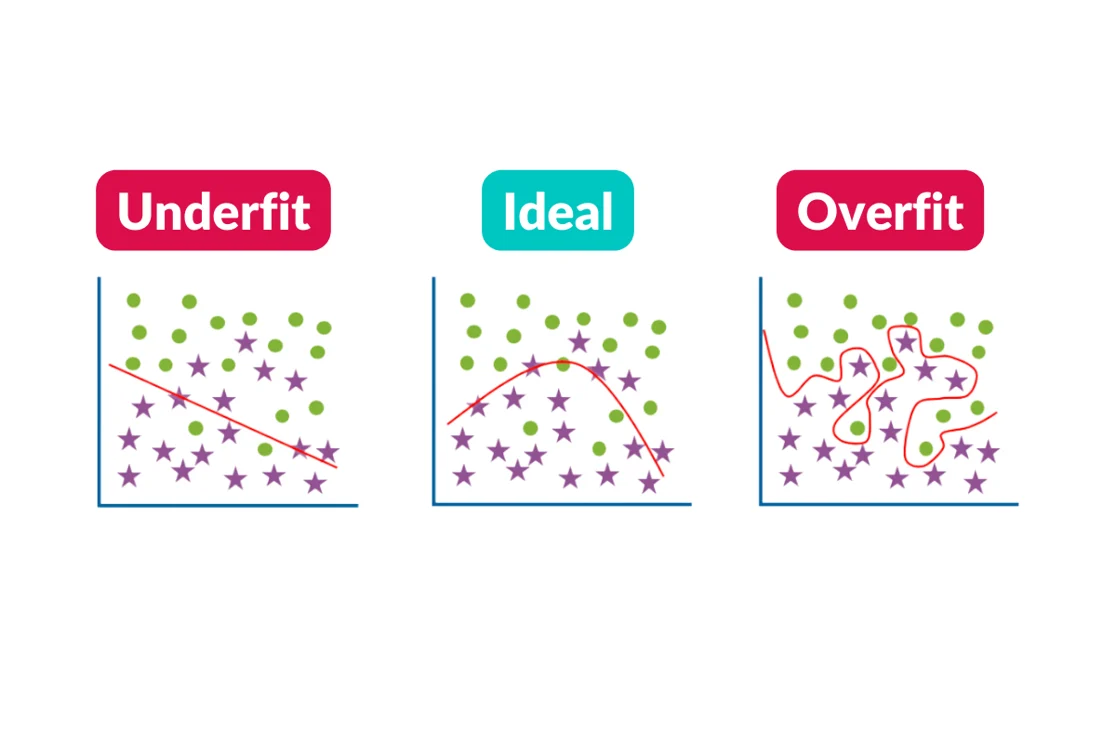
If your model is too deep, or in other words, you ask too many questions, you run the risk of over fitting. If you ask too few questions and don’t do a thorough job filtering out poor fits, you will under fit the audience and waste budget sending to households less likely to convert.
So you’re shooting for just right.
For this training model to be successful, you need to build lots (as in hundreds/thousands) of random forest models that account for thousands of variables, not just one or two.
Your end result will be a highly vetted custom audience with a high probability of achieving the goal of your model as a result of thousands of data points and qualifying questions.
But what if you have a larger audience size?
Enter deep learning.
What is Deep Learning?
Deep learning excels when your data set is very large and/or complex and is generally unstructured.
It’s like a random forest on steroids but embodies a different architecture.
What I mean by architecture is the process data must go through before an output is delivered.
To be accurately classified as a deep learning model, each feature of the model is assigned a value of importance or weight.
The larger the number, the more value it holds to us when delivering an output.
Then, the data needs to pass through at least three layers of pattern recognition, with each subsequent layer identifying new abstract patterns that a random forest wouldn’t be able to recognize.
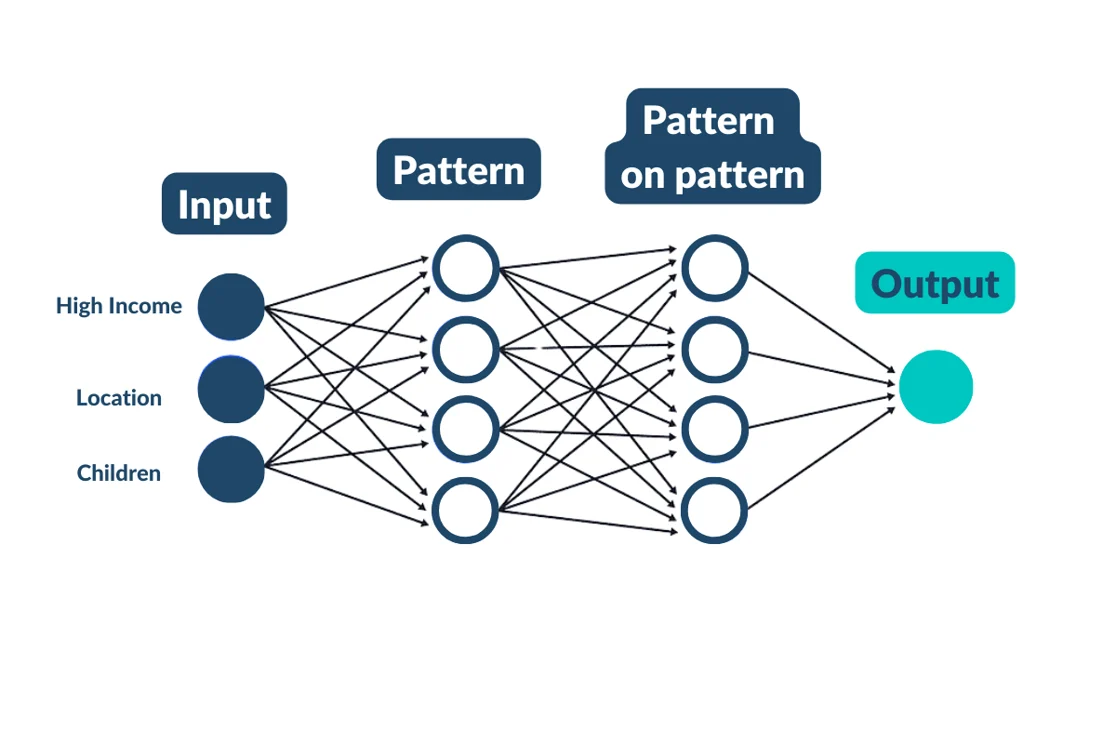
The result is a variety of households grouped together through complex pattern recognition.
Because the level of granularity data goes through in a deep learning model, the output looks much different than the output from a random forest, even if you used the same input data.
At Postie, we don’t just use this model when audience sizes are larger; we also use it when we are looking to build models to target customer traits that are more abstract and less distinct.
Take a flooring company versus a luxury goods company. The two customer groups will be very different.
While the luxury goods companies’ customer base will have some very distinct features (i.e. high income), the flooring companies’ customer base will be harder to define.
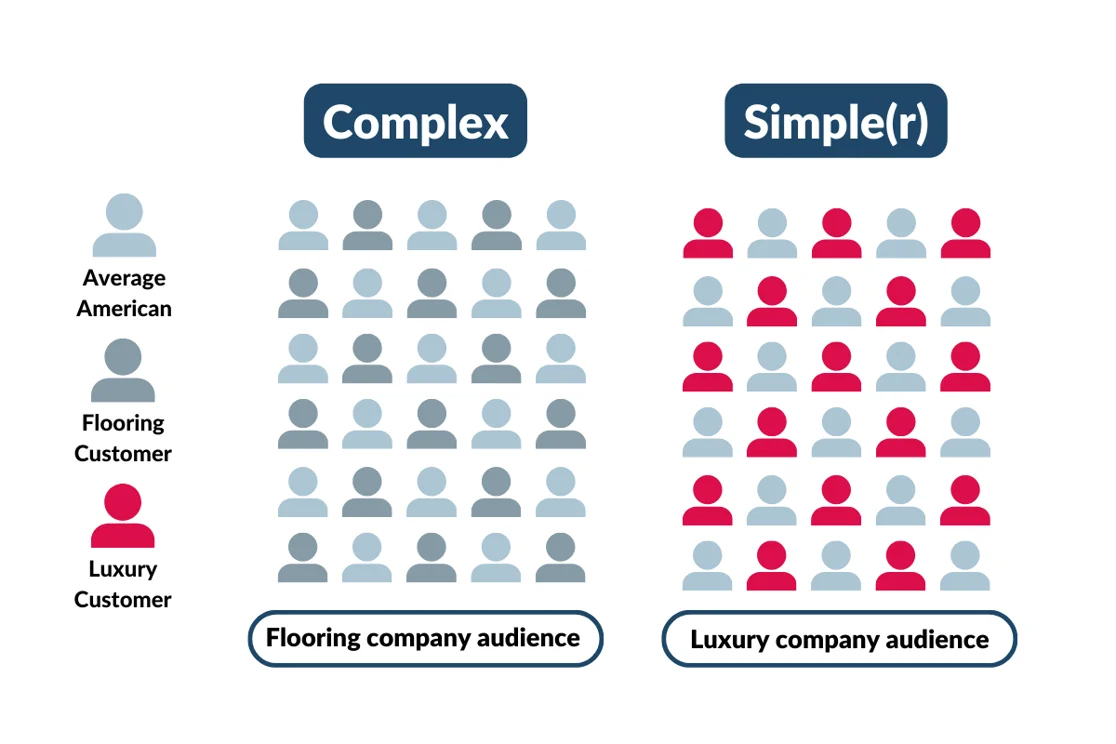
The flooring company’s customer base will be more reflective of the average American, and their propensity to be a good fit will be less about a certain set of features and more weighted on timing.
You can’t classify timing with a series of yes/no questions. In that case, we would deploy a deep learning model to find complex patterns that differentiate households that are more likely to purchase new flooring even though at first glance they all look the same.
Recap, Take 1
Supervised machine learning is used when working with labeled data to uncover patterns to group households to target during your marketing campaigns.
Based on the complexity and size of your data, you can deploy deep learning or random forest to train your models.
Random forest excels when the audience size is smaller, the level of data complexity is less, and there are standout features that make it easy to classify a good fit.
Deep learning steps in when the seed audience size is larger (minimum 20k), the data is more complex (pattern recognition is more challenging), and the variable we are trying to isolate is more abstract.
Let’s move on.
What is Unsupervised Machine Learning (UML)
Earlier in this post, I gave UML a very concise definition: a type of machine learning that does NOT need human input to complete its task. But there’s a lot more to UML. Let’s begin with three key differences between SML and UML.

- SML requires labeled data; UML does not
- SML requires “training,” UML does not
- SML is used to identify a “right answer,” UML has no “right answer”
Right vs. Wrong vs. Indifferent
A key differentiator between the two types of ML is the existence or lack of a “correct answer.”
Let me explain.
When we employ a supervised machine learning model to a problem it has a desired outcome. For example, correctly identifying spam email vs not spam email.
When we apply unsupervised machine learning, there is no “correct answer.” The model isn’t meant to identify an already known value. Instead, we’re trying to achieve pattern recognition from an unlabeled data set.
For example, you can use UML to comb through your unlabeled CRM data and uncover patterns between customers and then cluster them based on their similarities.
In this example, there is no right or wrong answer, just patterns. Now, the patterns that are uncovered can vary in usefulness, and a large part of the usefulness of the outcome has to do with the data you input and the planned use of the output.
We’ll talk about that more in a minute.
Unlabeled vs Labeled Data
In the spam email example above, to successfully train a model to correctly identify a piece of spam mail you first need to tell the model what is spam and what isn’t.
That’s where labeling comes in. Once the model can reference a label, it can then look at associated data variables that help it to build a deeper understanding of characteristics spam emails share. Think of words like FREE in the subject line.

Once it has a rich understanding of unique spam email characteristics, it can then accurately identify spam emails that exist outside of your data set that aren’t labeled.
On the flip side, with unsupervised machine learning, since the model isn’t tasked with finding a predetermined “correct answer,” the data it can be fed does not have to be labeled to help train the model.
But, we also can’t feed the algorithm completely raw data. We’ll cover our process a little later.
Training vs. No Training
With supervised machine learning we talked a lot about the different ways to train our model (deep learning, random forest, etc.) to help it develop a high level of accuracy when predicting outcomes.
With unsupervised we don’t deploy any training because, like I mentioned earlier, there are no right answers we need to train the model to identify. There are just patterns we use to cluster audiences that then get used in our marketing campaigns.
Preparing our Data
I’ve said it already and I’ll say it again: with unsupervised machine learning, there’s no wrong answers, just patterns.
But our desired application, how we prepare our data, and the initial data we select can all influence whether or not the results of our model provide any practical value.
To give yourself the best chance of coming away with a series of clusters you can’t wait to include in your next marketing campaign I’m going to share our data engineering approach.
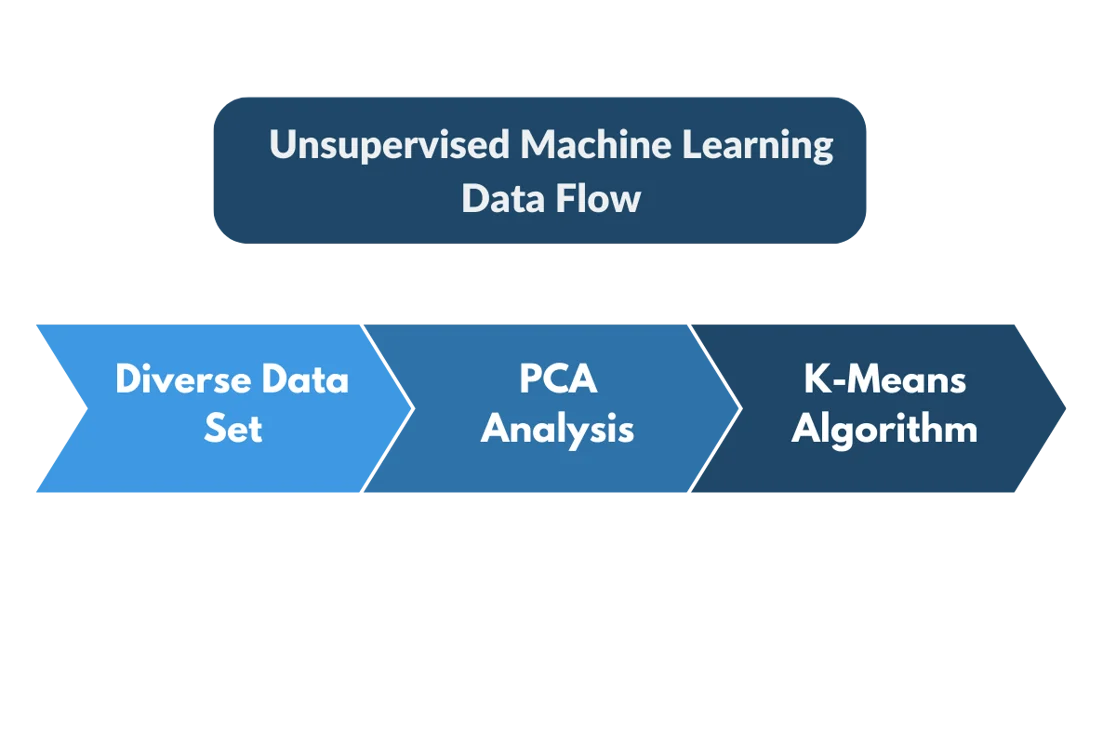
Step 1:
First off, make sure the data set you’re importing is diverse. If you’re importing a data set of people who you know to be incredibly similar to one another, think a list of customers who all bought the same product, live in the same area and have the same general income, the outcome of that data set will be pretty boring.
In large part, this is because even though the algorithm could find differences between them, the differences will be generally so insignificant that it’ll be like splitting hairs and won’t provide any actionable insight.
Step 2:
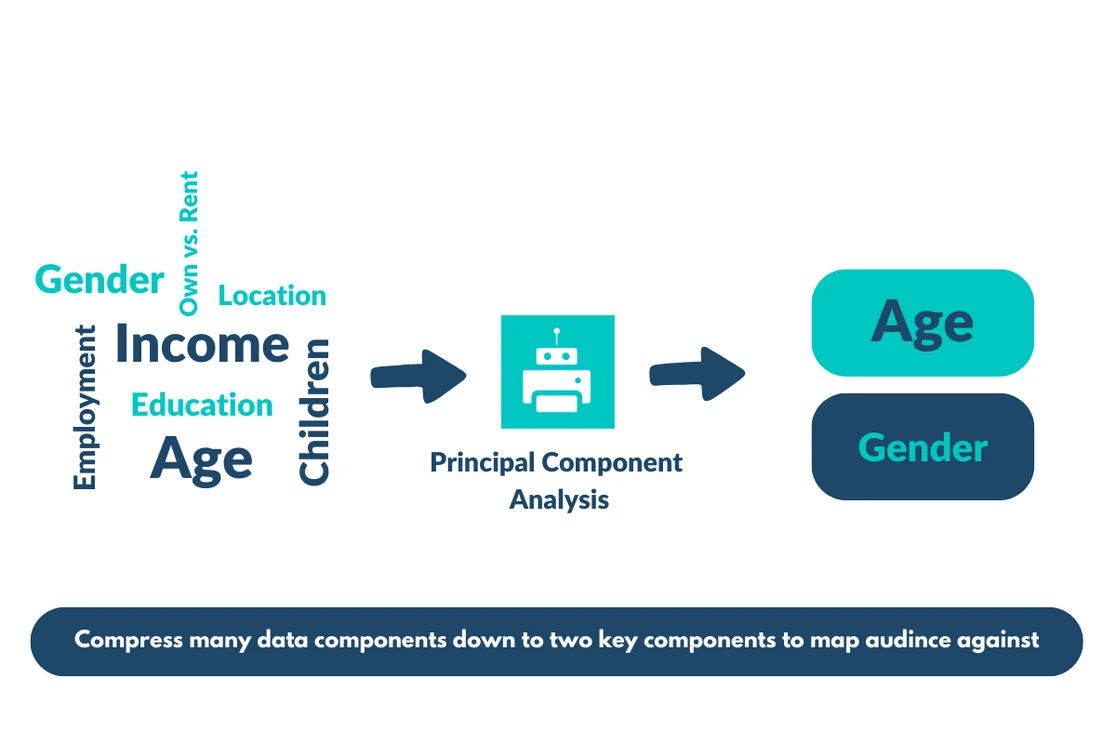
Once you’ve settled on a relevant and diverse data set to cluster, you’ll want to identify the variables that highlight the biggest variation between customers. We largely do this because most data sets have hundreds or thousands of dimensions and that makes it nearly impossible to map.
Instead, we apply a principal component analysis (PCA) that takes the hundreds/thousands of dimensions and compresses them into a much smaller quantity that is easily mappable – usually around 2.
These two components become the X and Y axes on our graph that we plot the members of our audience against. It’s like magic but is also firmly rooted in data science fundamentals.
Step 3:
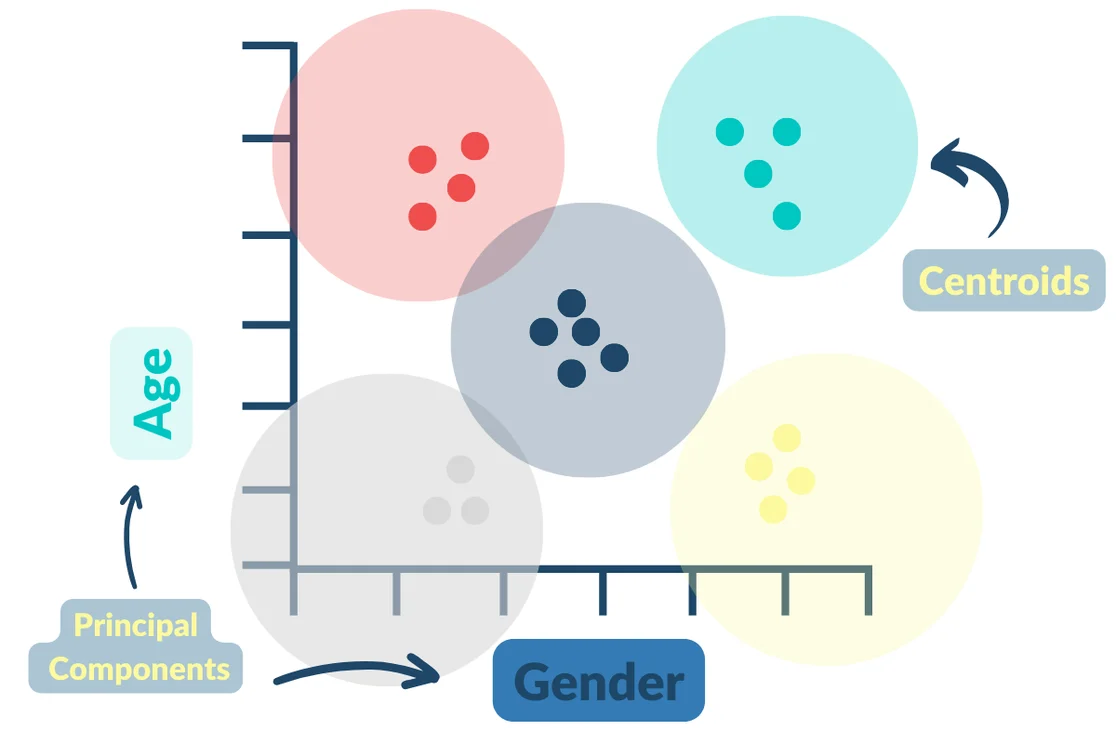
Lastly, once we’ve condensed our data with a PCA analysis, and plotted our audience on our graph, we run it through an algorithm called K-means clustering.
K-means is designed to break up our graph into different sections called centroids. The number of centroids is predetermined, but the location of the centroids is random. Inevitably, based on a contacts location on our graph, a group of our audience will fall within one centroid, while another group will fall into a different centroid, and so on and so forth.
These centroids eventually become our clusters. We repeat this process a couple of times to develop optimized clusters representing individuals with similar characteristics or propensities to complete the desired action.
What Now?
The unsupervised machine learning stage of this process is complete. Thanks to our UML model we have uncovered a variety of patterns and grouped our audience into clusters based on where they fell within the centroids of our PCA analysis.
But a UML model can’t tell us what to do with these clusters, that’s up to us as savvy marketers to apply them in ways that deliver results. So if you’re looking for different kinds of campaigns to use your shiny new clusters in, our guide 7 Campaigns Every Digital Marketer Must Try is a great place to start.
Recap, Take 2
Unsupervised machine learning models are not tasked with finding a “correct answer.” Instead, they identify patterns.
Since there is no “correct answer,” we don’t need to train a UML model, but we do need to be diligent about preparing our data before running it through the model to ensure that our outputs are actionable.
UMLs don’t require human intervention, but they won’t tell us how to apply the outputs and that is where our expertise as marketers comes in and specifically where Postie shines. Want to see for yourself, book a demo today!
