When you work with Postie, you will often hear us talk about data sets and data models. When running a campaign, we usually suggest testing different data providers to see which one performs better. If you have been with us for a while, we might even recommend retesting a previously used data set. Yes, we know this topic can get complicated, so let’s break it down casual interview style.
Q: Can you please tell me more about data sets and 3rd party data providers?
A: Of course. As their name implies, data sets are sets of data that contain information on the US population. It helps to think of them as massive excel sheets with tons of rows and columns filled with raw data. Raw data can include a mix of demographic, spend, interest & behavioral information tied to a given individual.
There are several 3rd party data providers in the US, each with its own data set. At Postie, we work with three industry-leading providers: Acxiom, Epsilon, and Experian.
Q: Now, what is the role of data models?
A: Data models process and organize information; they use algorithms to identify complex patterns within the raw data.
When Postie builds a lookalike audience for a direct mail campaign, we run a Postie model. The model’s output ranks all the individuals in the addressable market based on how similar they are to your customers. Without the model, it would be impossible to build an effective lookalike audience.
Q: Does this imply that Postie has its own data models?
A: It certainly does! One of the things that set Postie apart is our proprietary modeling. We’ve made a significant investment in industry-leading technology, a robust machine learning platform, and a team of visionary PhDs to develop top-performing models.
So, while anyone can purchase the 3rd party data sets, the Postie data models are proprietary, and you won’t find them anywhere else. Additionally, we make a unique model for each data set to ensure we are leveraging each data set optimally.
Q: Can we go back to data sets for a sec? Why does Postie use three?
A: Good Question. There are two main reasons.
First: Just like diversity makes teams better, it also makes data science better! Each data set has unique features and strengths. For example, one might have excellent behavioral purchase data, while another might contain very accurate credit data. Using multiple data sets, we can access different types of information.
Second: This gets more technical: The way individuals are classified differs between data sets, meaning that the same individual can be described or identified differently in each data set.
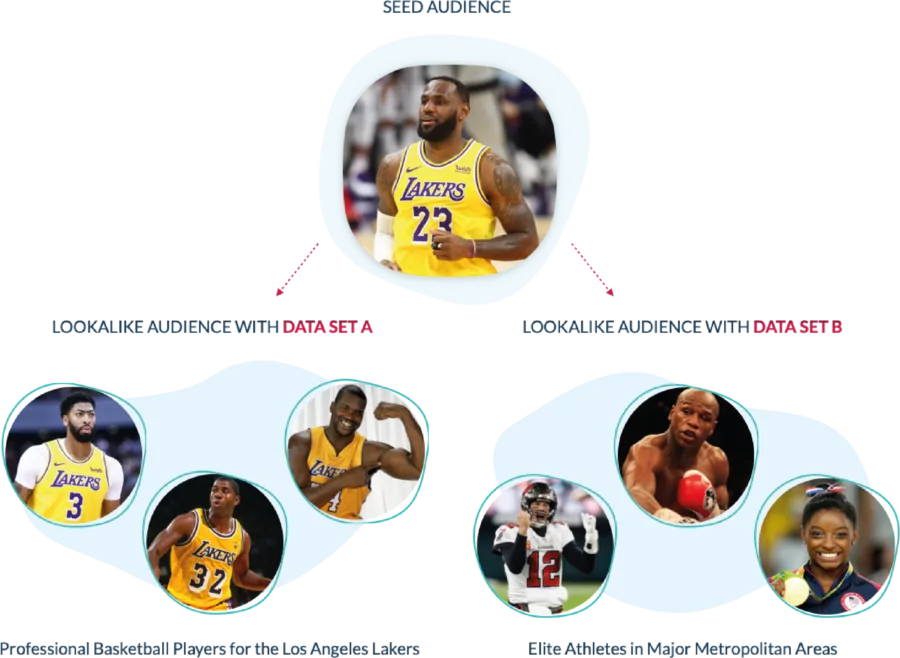
An example can help; let’s say we want to see how Lebron James could be classified in two different data sets. Data set A classifies him as a basketball player for the Los Angeles Lakers, while data set B classifies him as an elite athlete that lives in or near a major metropolitan area. Both are accurate, but they are not the same.
Q: Why does it matter how Lebron James is classified?
A: It matters because it will make a difference when creating a lookalike audience. Imagine Lebron James is a customer within your CRM, and therefore the seed audience for your model.
Suppose you run a lookalike model using data set A. In that case, the model will prioritize identifying other pro basketball players who’ve played for Los Angeles Lakers, like Magic Johnson, Shaquille O’Neal, and Anthony Davis.
Now suppose you run a model using data set B. In this case, your lookalike audience will highly rank other elite athletes living in or near major metropolitan areas, like Tom Brady, Floyd Mayweather, and Simone Biles.
Let’s tie that back to your Direct Mail campaigns. There are some scenarios where you might want to find prospective customers that are nearly identical to your existing customers, but for other campaigns using a broader lens to find the best prospective customers could be wiser.
One Seed Audience Two Different Lookalike Audiences
This is why Postie uses a variety of 3rd party data sets and builds its own proprietary models; we have numerous levers we can adjust to optimize campaigns.
Q: Makes sense! So how do I know which data set to use?
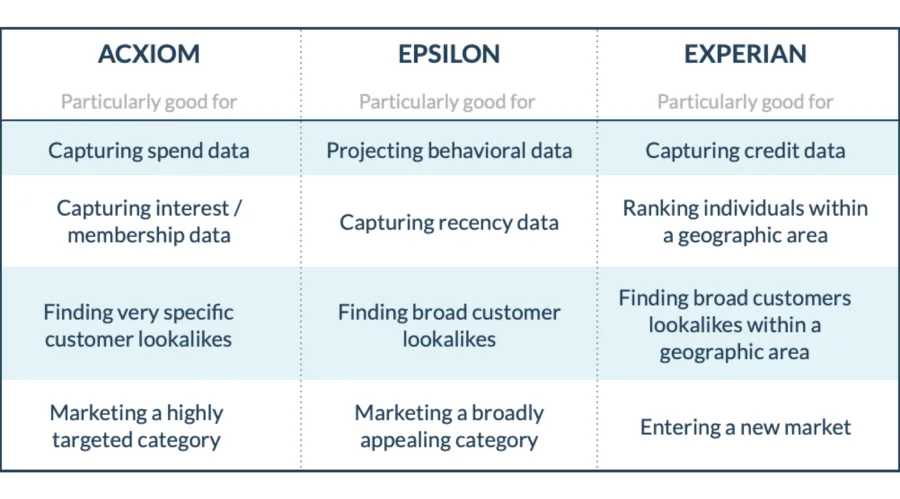
A: Like any data, math, or science-driven enterprise will tell you, we won’t know until we can test it, and this is why we recommend trying different data sets. As a general set of guidelines, the table below highlights some of the differences between the data sets we consider when building a test matrix.
You can, but we wouldn’t recommend it. Four variables can change over time, making it worthwhile to retest in the future.
A. Decay in the model/data set combination:
Because data models rank the customers in a data set, you will usually mail the top-ranked customers when you start a campaign. As you mail more individuals, you go further down the model, and performance can eventually degrade.
B. Your CRM list:
The makeup of your customers changes over time. An updated CRM list might require a different data set that better captures the characteristics of your new audience.
C. The data sets:
Every data provider updates their data sets multiple times a year. A new source of data can also impact your campaigns.
D. Postie’s models:
We are continually improving. As we gain new learnings, we adjust our models to optimize performance. A new model can significantly improve the performance of a data set, lifting it above another.
Q: That was great! Anything else I should know?
A: So happy that this clears things up. We have to admit that we did simplify how these data sets and models work for this explanation. If you have more complex questions, we can tackle them in detail with our data science team.
